
3.6. Sampling Distribution of the Mean#
Often, we are not interested in the individual data points in a sample or the distribution, but rather in a summary statistic such as the mean. For example, later on in the course, we will ask questions like:
Is the mean height of Oxford students greater than the national average?
Is the mean wellbeing of cat owners higher than that of non-cat-owners?
To answer these questions we will want to estimate the population mean (mean height of all Oxford students, mean wellbeing score of all cat owners) based on the data from a sample.
Therefore, to understand how much we can trust small observed differences (for example, if the mean height in our Oxford sample is 1 mm taller than the national average — is that just chance?), we need to answer the following question:
How well does the sample mean reflects the underlying population mean?
We can operationalize this as :
If I drew many different samples from the same population, how much would the sample mean vary from sample to sample?
We can actually simulate this process — for example, by drawing 1,000 samples from the same population and plotting their means. The resulting distribution of those sample means is called the sampling distribution of the mean.
3.6.1. Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import seaborn as sns
sns.set_theme(style='white')
import statsmodels.api as sm
import statsmodels.formula.api as smf
import warnings
warnings.simplefilter('ignore', category=FutureWarning)
3.6.2. Load and plot the data#
We continue with the fictional Brexdex dataset.
First load the data, a set of 10,000 responses. The dataset (10,000 responses) is large enough that we can assume the distribution is quite representative of the population as a whole; we will refer to this as the parent distribution.
UKBrexdex=pd.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook_2024/main/data/UKBrexdex.csv')
sns.histplot(data=UKBrexdex, x='score', bins=range(101))
plt.plot([UKBrexdex.score.mean(),UKBrexdex.score.mean()], [0,250], 'r')
plt.xlabel('score on BrexDex')
plt.ylabel('frequency')
plt.show()
print('the mean score of the parent distribution is : ' + str(UKBrexdex.score.mean()))
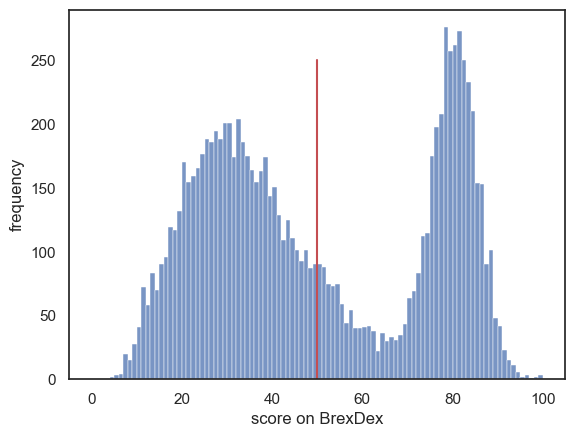
the mean score of the parent distribution is : 49.8748
3.6.3. 10,000 sample means#
The mean Brexdex score obtained from the parent distribution is 49.9%.
We have seen on previous pages that the data distribution in small samples (say, \(n=20\) or \(n=100\)) resembles the parent distribution, so we might expect that the mean of each of these samples approximates the mean of the UK national sample.
To test that we will start by visualising a few samples with the mean included.
plt.figure(figsize = (12,9))
for i in range(1,13):
sample = UKBrexdex.sample(n=100, replace=False)
m = sample.score.mean()
plt.subplot(3,4,i)
sns.histplot(sample.score, bins=range(0,101,5), kde=True) # use wider bins for the sample as there are fewer datapoints A
plt.plot([m, m], [0,15], 'r')
plt.tight_layout()
plt.show()
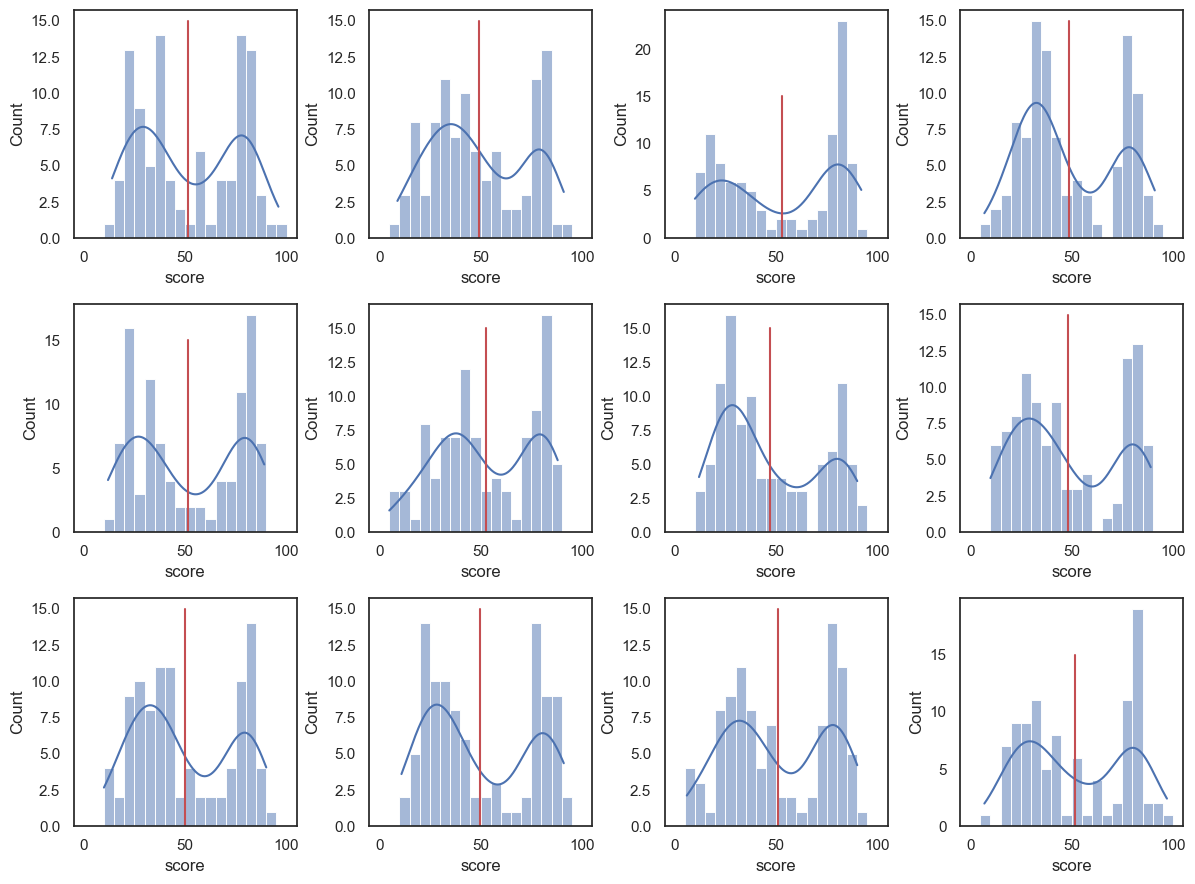
Okay, instead of doing this 12 times let’s try drawing a large number of random samples with \(n=100\), and getting the mean of each one. Below we will draw 10,000 samples of 100 from the parent distribution. Each time we will calculate the mean of the sample and store that mean.
nSamples = 10000 # we will draw 10,000 samples
samplesize=100 # each sample contains n people
m=np.empty(nSamples) # make an array to store the means
for i in range(nSamples):
sample = UKBrexdex.sample(n=samplesize, replace=False)
m[i]=sample.score.mean()
Finally, we can plot a histogram of the resulting means:
sns.histplot(m)
plt.plot([UKBrexdex.score.mean(), UKBrexdex.score.mean()],[0,600],'r-') # add a line for the population mean
plt.xlabel('sample mean')
plt.show()
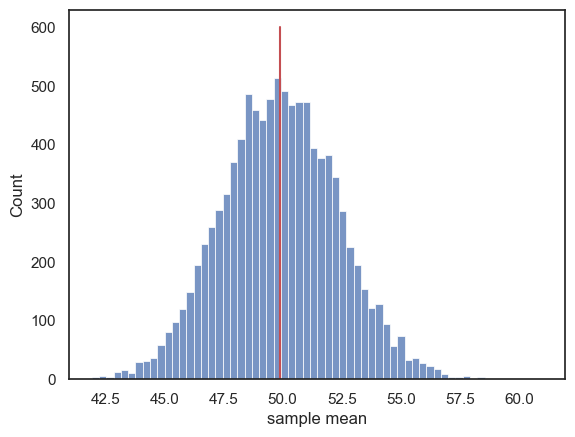
This distribution is the sampling distribution of the mean.
We can see that the sample means are clustered around the mean of the parent distribution (indicated by the red line).
3.6.4. Smaller samples, more variability#
We saw previously that for smaller sample sizes, there is more random variability in the sample distribution. Naturally this means that the sample mean also varies more from sample to sample, when the sample size is small.
Let’s repeat the exercise above, but comparing sample size of \(n=20\), \(n=100\) and \(n=1000\):
# You wouldn't be expected to produce this code yourself!
samplesize=[20,100,1000]
nSamples = 10000
plt.figure(figsize=[10,6])
for j in range(len(samplesize)):
plt.subplot(2,3,j+1)
for i in range(20):
sample = UKBrexdex.sample(n=samplesize[j],replace=False)
sns.kdeplot(sample.score, color='k', alpha=0.3, bw_adjust=0.5) # note I manually changed the smoothing of the KDS plot - this is a bit tangential to the point of the exercise though so don't get distracted by it
plt.xlim([0,100])
plt.ylim([0, 0.03])
sns.kdeplot(UKBrexdex.score,color='r')
plt.title('n = ' + str(samplesize[j]))
plt.subplot(2,3,j+4)
m=np.empty(nSamples) # make an array to store the means
for i in range(nSamples):
sample = UKBrexdex.sample(n=samplesize[j],replace=False)
m[i] = sample.score.mean()
sns.histplot(m, bins=range(30,70))
plt.plot([UKBrexdex.score.mean(), UKBrexdex.score.mean()],[0,4500],'r-') # add a line for the population mean
plt.xlabel('sample mean')
plt.tight_layout()
plt.show()
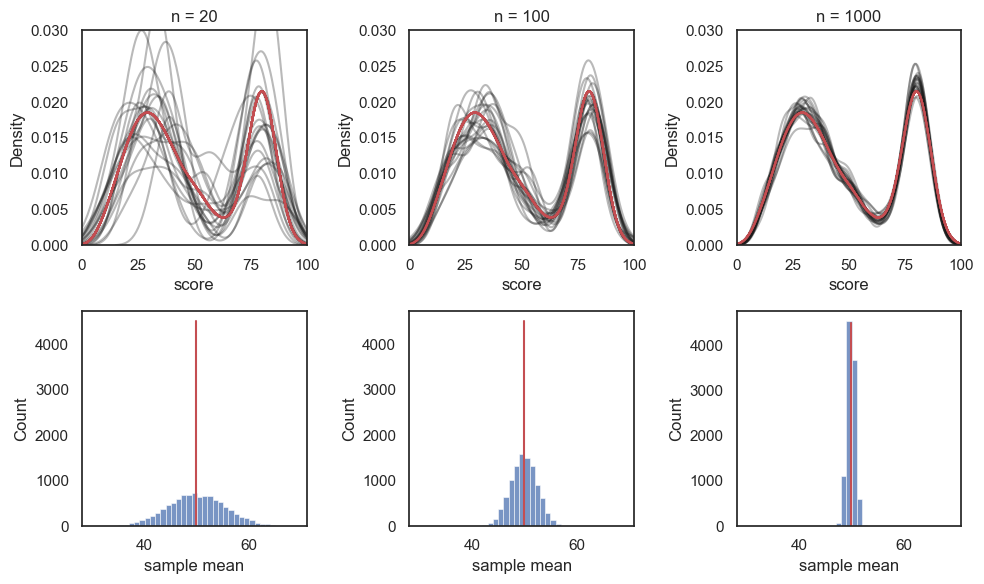
Top row: As the sample size increases, the data distribution within each sample (black lines) conforms more closely to the parent data distribution (red line)
Bottom row: sample mean for 10,000 samples at each sample size - as the sample size increases, the random variation in the sample mean decreases. For large smaples, the sample mean tends to be very close to the mean of the parent distribution.
3.6.5. Standard Error of the mean#
Although the sample means tend to cluster around the mean of the parent distrbution, there is still some random variation, as some samples (by chance) contain higher Brexdex scores than others.
The variability of the sample means is quantified by the standard deviation of the sampling distribution of the mean. That is, the standard deviation of the values shown in the histogram above. This is called the standard error of the mean (SEM). As you can see above, the SEM becomes smaller as the sample size increases, that is, the histograms get narrower, whereas larger samples give more stable and precise estimates of the population mean.
The standard error of the mean is represented by the formula:
… where \(\sigma\) is the standard deviation of the parent distribution, which in this case where we (unusually) have access to the parent distribution of 10000 individuals, we can obtain as follows:
print(UKBrexdex.score.std())
24.79272056187634
We can confirm the formula for the SEM gives us a match to the standard deviation of the sampling distribution of the mean
# run simulation for samples of size 100
nSamples = 10000 # we will draw 10,000 samples
samplesize=100 # each sample contains n people
m=np.empty(nSamples) # make an array to store the means
for i in range(nSamples):
sample = UKBrexdex.sample(n=samplesize, replace=False)
m[i]=sample.score.mean()
print('sd of sampling distribution (from simulation) = ' + str(m.std()))
SEM = UKBrexdex.score.std()/(samplesize**0.5) # n to the power 0.5 is sqrt of n
print('SEM from the formula = ' + str(SEM))
sd of sampling distribution (from simulation) = 2.481097498519355
SEM from the formula = 2.479272056187634
This is not a bad match!
You can try changing the sample size \(n\) and check it still works.
3.6.6. \(SEM \propto \frac{1}{\sqrt{n}} \)#
The standard error of the mean is inversely proportional to \(\sqrt{n}\)
In other words, the random variability in sample means decreases as sample size \(n\) increases - but in proportion to \(\sqrt{n}\) not \(n\) itself
This means that as we increase our sample size, our estimate of the population mean becomes less uncertain. However, the benefit of adding more participants gradually diminishes, e.g., doubling your sample size doesn’t halve your uncertainty; instead, it reduces it by a factor of \(\sqrt{2}\) (~1.4).